背景
负载均衡是分布式系统里最常用的能力,他的实现方式有很多,轮询,随机,加权轮询,一致性hash等网上文章很多,可以自行查阅,今天要讲的是遇到的一个真实的生产的问题。
公司内部的ES访问架构一般是, Java应用--->SLB(域名)---->ES ingest node (no data) --> ES data node ,其中ingest节点是对外暴露的,供Java应用访问,承担了一个纯client角色,不提供数据存储和倒排索引检索服务。这其中SLB是为了方便起到一个域名和负载均衡的功能,绑定后端的n个client节点,并且做到对业务透明,但是毕竟还是有开销的,多了一次网络rpc的转发(尽管他很快),同时也是多花了一份钱。所以在930的时候我们把SLB去掉了,并且进行了验证完全没有问题,这其中还要得益于es本身就支持ip配置列表,并且自身实现了负载均衡的功能。 更改之后的访问链路,Java应用--->ES ingest node -->ES data node
就在缩容的时候,我们遇到了问题,我们更改了es client里面配置的ip列表,结果出现了超时,同时观察到一个现象,每次更新ip 列表的时候,总有一台机器的连接数明显高于其他机器,这是为何呢?关键节点如下
- step1 下午16:xx 更新了es client里的机器列表,系统表现正常
- step2 晚上20:5x 开始下线数据节点,系统出现了少量超时和报错,并且观察到有一台es的client节点流量明显高于其他机器,出现了负载不均衡
- step3 晚上21:1x 以为es 流量高的节点有问题,所以进行了下线
- step4 晚上21:2x 随着那台client节点下线,另外一台新的client节点又出现了流量过高的情况,并且超时一波一波,像是定时发生的
- step5 怀疑是不是es client sdk 初始化有问题,代码里创建了新的es client的时候,老的未正常销毁,于是开始分批重启Java应用,让他重新初始化es client,而不是做热替换,分6批,每批大概10台机器
- step6 观察到超时依然持续,负载不均衡的问题,依然没有解决,同时超时从一波波变成了持续但是少量,相当于原来超时的波峰被均匀打散到各个时间段了
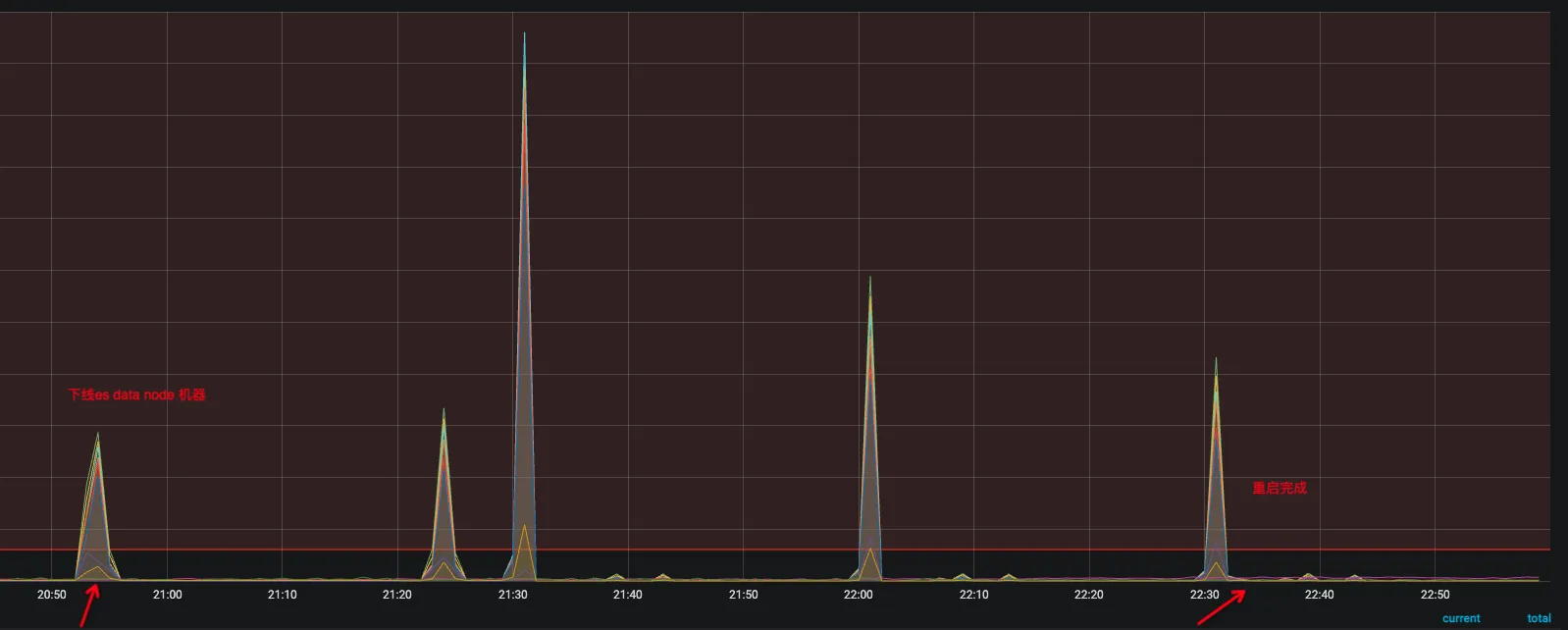
- step7 随后发现,es client里的ip列表配错了,里面配置了data node 数据节点,而正好20:5x下线了这几台机器,这几台已经不可用了
- step8 修正es client连接的ip列表,系统报错消失,负载又均衡了,系统恢复正常
问题
从负载不均衡的表现上来看,应该是配置的ip列表了,有机器不可用了,那么这台机器的下一台可用的机器,流量就会比别的机器明显高,出现了负载不均衡的问题,应该是es的负载均衡的逻辑导致的,因此决定翻一翻es的负载均衡的算法,详细的看看。
先抽象一下问题,在RR的负载均衡算法下,
有 ServerA, ServerB,ServerC,ServerD,ServerE 5台机器,当ServerD不可用的时候,ServerE的流量会明显增高,当ServerE不可用的时候,ServerA的流量会明显增高。
1.为什么轮询的负载均衡算法里,坏节点的下一台机器流量会明显高?- 为什么会超时?为什么超时最开始一波波的,重启后超时会打散了?
- ES是如何处理es client里的坏节点的? 如果是加黑名单,为什么还会出现负载不均衡和超时问题?
源码分析
整体流程
抽茧剥丝,去掉所有干扰因素,今天就主要看看es的负载均衡的实现,过程不细说,直接上答案
/** * Sends a request to the Elasticsearch cluster that the client points to. * Blocks until the request is completed and returns its response or fails * by throwing an exception. Selects a host out of the provided ones in a * round-robin fashion. Failing hosts are marked dead and retried after a * certain amount of time (minimum 1 minute, maximum 30 minutes), depending * on how many times they previously failed (the more failures, the later * they will be retried). In case of failures all of the alive nodes (or * dead nodes that deserve a retry) are retried until one responds or none * of them does, in which case an {@link IOException} will be thrown. * * This method works by performing an asynchronous call and waiting * for the result. If the asynchronous call throws an exception we wrap * it and rethrow it so that the stack trace attached to the exception * contains the call site. While we attempt to preserve the original * exception this isn't always possible and likely haven't covered all of * the cases. You can get the original exception from * {@link Exception#getCause()}. * * @param request the request to perform * @return the response returned by Elasticsearch * @throws IOException in case of a problem or the connection was aborted * @throws ClientProtocolException in case of an http protocol error * @throws ResponseException in case Elasticsearch responded with a status code that indicated an error */ public Response performRequest(Request request) throws IOException { InternalRequest internalRequest = new InternalRequest(request); return performRequest(nextNodes(), internalRequest, null); }这里有个nextNodes() ,返回值是一个NodeTuple<Iterator
>�是一个服务器列表,暂且不去看他怎么调整的,看看他怎么用的(分析过程需要理解es是怎么使用Apache的httpclient去请求服务器的,这里直接公布答案,host信息会带在request里面构造成一个类似 HttpGet("https://host:port/search?q=0")这样的一个对象传给httpclient执行,)从后面使用的地方来看,try里面选中的是nodeTuple.nodes.next(), 由于这是第一次从list里取数据,因此是头结点。 //取了数组的第一个做为第一次请求host RequestContext context = request.createContextForNextAttempt(nodeTuple.nodes.next(), nodeTuple.authCache);
注释说的很清楚,使用了RR负载均衡算法,并且错误的节点会被静默处理(加入黑名单,1分钟,最大30分钟 )
Selects a host out of the provided ones in a round-robin fashion. Failing hosts are marked dead and retried after a certain amount of time (minimum 1 minute, maximum 30 minutes)
来到了这个关键代码,nextNodes,是干什么的? 他其实是对原来的列表进行了排序并且剔除了dead node .
```java
static Iterable<Node> selectNodes(NodeTuple<List<Node>> nodeTuple, Map<HttpHost, DeadHostState> blacklist,
AtomicInteger lastNodeIndex, NodeSelector nodeSelector) throws IOException {
/*
* Sort the nodes into living and dead lists.
*/
List<Node> livingNodes = new ArrayList<>(Math.max(0, nodeTuple.nodes.size() - blacklist.size()));
List<DeadNode> deadNodes = new ArrayList<>(blacklist.size());
for (Node node : nodeTuple.nodes) {
DeadHostState deadness = blacklist.get(node.getHost());
if (deadness == null || deadness.shallBeRetried()) {
livingNodes.add(node);
} else {
deadNodes.add(new DeadNode(node, deadness));
}
}
if (false == livingNodes.isEmpty()) {
/*
* Normal state: there is at least one living node. If the
* selector is ok with any over the living nodes then use them
* for the request.
*/
List<Node> selectedLivingNodes = new ArrayList<>(livingNodes);
nodeSelector.select(selectedLivingNodes);
if (false == selectedLivingNodes.isEmpty()) {
/*
* Rotate the list using a global counter as the distance so subsequent
* requests will try the nodes in a different order.
*/
Collections.rotate(selectedLivingNodes, lastNodeIndex.getAndIncrement());
return selectedLivingNodes;
}
}这里有几个关键信息,
- 要返回的列表是new 出来的,跟原来的你配置进去的不干扰
- 如果有死节点,这里就直接清理掉了,关键判断逻辑 deadness.shallBeRetried()稍后介绍
- 使用的是集合的Collections.rotate()实现了轮询机制,稍后介绍
- 轮询的之后返回的是一个调整完排序的新的列表给到performRequest�调用next()获取了第一个节点
- rotate的第二个参数rotate�是多个线程同时共享使用的,每次+1, 因此实现了轮询的作用
轮询算法
过程如下,假如原来你配置的列表, A,B,C,D,假设正常情况没有坏节点的情况下
第一次Collections.rotate("A,B,C,D", 0) = "A,B,C,D"�
第二次lastNodeIndex=1,Collections.rotate("A,B,C,D", 1) = "D,A,B,C"�
第三次lastNodeIndex=2,Collections.rotate("A,B,C,D", 2) = "C,D,A,B"�
第四次lastNodeIndex=3,Collections.rotate("A,B,C,D", 3) = "B,C,D,A"�
第五次lastNodeIndex=4,Collections.rotate("A,B,C,D", 4) = "A,B,C,D"
后面就是重复了,可以看到第一个参数始终不变,变动的是第二个参数,实现了一个环状的滚动�
其中这几次的调用,不一定是同一个线程,因此可能是并发进行的,第二个参数是一个AtomicInteger�对象,保证了线程的安全性。
注入选择逻辑
需要提一下的是,这里面有个NodeSelector�对象干扰,可以看到,在调用rotate之前,调用了这个对象的select方法,点进去看到的是一个接口,那么这里很大概率就是一个扩展点了,真实的我们在用的时候,有个默认值,NodeSelector ANY�,他的方法体里是个空的,什么也没做,也就是默认,什么都不做,所以这个是没用的,不用去关心
/**
* Select the {@link Node}s to which to send requests. This is called with
* a mutable {@link Iterable} of {@linkplain Node}s in the order that the
* rest client would prefer to use them and implementers should remove
* nodes from the that should not receive the request. Implementers may
* iterate the nodes as many times as they need.
* <p>
* This may be called twice per request: first for "living" nodes that
* have not been blacklisted by previous errors. If the selector removes
* all nodes from the list or if there aren't any living nodes then the
* {@link RestClient} will call this method with a list of "dead" nodes.
* <p>
* Implementers should not rely on the ordering of the nodes.
*/
void select(Iterable<Node> nodes);坏节点的处理
如果出现了异常,就会走入到catch代码块里,
try {
httpResponse = client.execute(context.requestProducer, context.asyncResponseConsumer, context.context, null).get();
} catch(Exception e) {
RequestLogger.logFailedRequest(logger, request.httpRequest, context.node, e);
onFailure(context.node);
Exception cause = extractAndWrapCause(e);
addSuppressedException(previousException, cause);
if (nodeTuple.nodes.hasNext()) {
return performRequest(nodeTuple, request, cause);
}
if (cause instanceof IOException) {
throw (IOException) cause;
}
if (cause instanceof RuntimeException) {
throw (RuntimeException) cause;
}
throw new IllegalStateException("unexpected exception type: must be either RuntimeException or IOException", cause);
}这里面有两个关键信息
- onFailure(context.node) 把当前的这个节点加入黑名单里
- return performRequest(nodeTuple, request, cause);� 递归调用下一个节点,直到有正常节点响应
那么加入黑名单之后会发生什么呢? 从刚刚的select node 逻辑里可以看到,blackList节点里的节点需要通过shallBeRetried�的判断,要不要加入到living列表里,用来这次请求,这个方法如下
/**
* Indicates whether it's time to retry to failed host or not.
*
* @return true if the host should be retried, false otherwise
*/
boolean shallBeRetried() {
return timeSupplier.get() - deadUntilNanos > 0;
}timeSupplier.get()是当前时间
deadUntilNanos则是一个变量,决定了是否这个节点要被去静默处理(不请求)
第一次请求不通的时候,他等于当前时间加1分钟,也就是静默1分钟,再此后的1分钟内这个shallBeRetried返回的都是false,就是不需要重试,而这个1分钟会随着失败次数的增加越来越长。
DeadHostState(Supplier<Long> timeSupplier) {
this.failedAttempts = 1;
this.deadUntilNanos = timeSupplier.get() + MIN_CONNECTION_TIMEOUT_NANOS;
this.timeSupplier = timeSupplier;
}后面再次请求不通的时候,他静默的时长是一个算法,逐步加长的算法,例如,1分钟,3分钟,15分钟,30分钟最大30分钟,数值为举例,可以自行计算
/**
* Build the dead state of a host given its previous dead state. Useful when a host has been failing before, hence
* it already failed for one or more consecutive times. The more failed attempts we register the longer we wait
* to retry that same host again. Minimum is 1 minute (for a node the only failed once created
* through {@link #DeadHostState(Supplier)}), maximum is 30 minutes (for a node that failed more than 10 consecutive times)
*
* @param previousDeadHostState the previous state of the host which allows us to increase the wait till the next retry attempt
*/
DeadHostState(DeadHostState previousDeadHostState) {
long timeoutNanos = (long)Math.min(MIN_CONNECTION_TIMEOUT_NANOS * 2 * Math.pow(2, previousDeadHostState.failedAttempts * 0.5 - 1),
MAX_CONNECTION_TIMEOUT_NANOS);
this.deadUntilNanos = previousDeadHostState.timeSupplier.get() + timeoutNanos;
this.failedAttempts = previousDeadHostState.failedAttempts + 1;
this.timeSupplier = previousDeadHostState.timeSupplier;
}答案
源代码看完之后,尝试回答刚刚的问题
- 为什么会负载不均衡?
当其中一个节点坏了之后,他会启用重试逻辑,重试他下一个节点,直到正常,因此坏节点上面的流量全部挪给了下一个健康节点,因此出现了负载不均衡。
ps: 假如坏掉的是最后一个节点,ABCD的D坏了,根据条件if (nodeTuple.nodes.hasNext()) {}他不会重试了,为什么第一个节点会出现负载不均衡呢?
最开始这里困扰了一下,后来再详细的分析发现,performRequest�取的始终是排序变换完成之后的第一个节点,因此虽然你配置的是ABCD,D在最后一个,但是实际使用的时候,D一定是排第一个,这也就是刚刚为什么强调返回的对象是new的一个数组
- 为什么会超时?为什么超时最开始一波波的,重启后超时会打散了?
因为变更ip 列表是所有java机器几乎同时变更的,这个列表里有几个坏机器,因此触发了静默的逻辑,也就是第一次全部失败报错,然后静默了1分钟之后,再次请求,再次集体报错,下一次请求的节奏始终一致,因此这个超时是一波一波的像定时任务一样。
随后因为分批重启,client请求坏节点的时间被打散了,因此后面静默结束的时间也不一样,因此超时被分散了。
- 为什么加黑名单还会报错?
虽然会加黑名单,但是第一次请求还是报错了(但没有日志)。另外静默是会结束的,结束之后再请求,还是会报错。因此不健康的节点,也是会接受请求的。
另外值得一提的是,虽然你设置的是1.5s超时,但是因为这个重试逻辑,实际上的超时时间是大于1.5s的,如果里面有2个坏节点,那么就会超过3s,因此全链路也会等待超时,这让你看起来像是超时时间未设置生效一样。
结论
使用es restclient直接访问es集群的时候,通过ip直连而不是slb来连接的时候,由于es的负载均衡算法问题,会出现以下现象
- 一波一波的es访问超时,且没有日志。。。 (debug日志生产一般不开),重试时间过久会导致全链路超时
- 坏掉的节点的下一个节点上的流量会明显高于其他节点,负载不再均衡
- 全链路会报错,因为你配置的超时时间是每次请求es的Socket时间,而由于他自己会重试好几次,因此真实的search时间会超过你设置的超时时间,导致上游的soa cancel报错。这也是为什么es的响应头里告诉你took花了500ms,实际上你的search方法却花了1s的原因.
所以配置ip列表的时候,检查仔细了,不要配置无效节点,否则会因为重试逻辑导致你预料不到的情形