架构
-
什么是flink
flink是一个框架或者叫流式计算引擎,他可以用来处理有界(批处理,mapReduce)数据和无界数据。他的特点是具有内存的速度和分布式的横向扩展能力。由于是分布式的,所以他可以处理任意规模的数据。另外,他是有状态的,表现为上一步的结算结果可以为下一步使用。
有界和无界的解释,见下面的图。

-
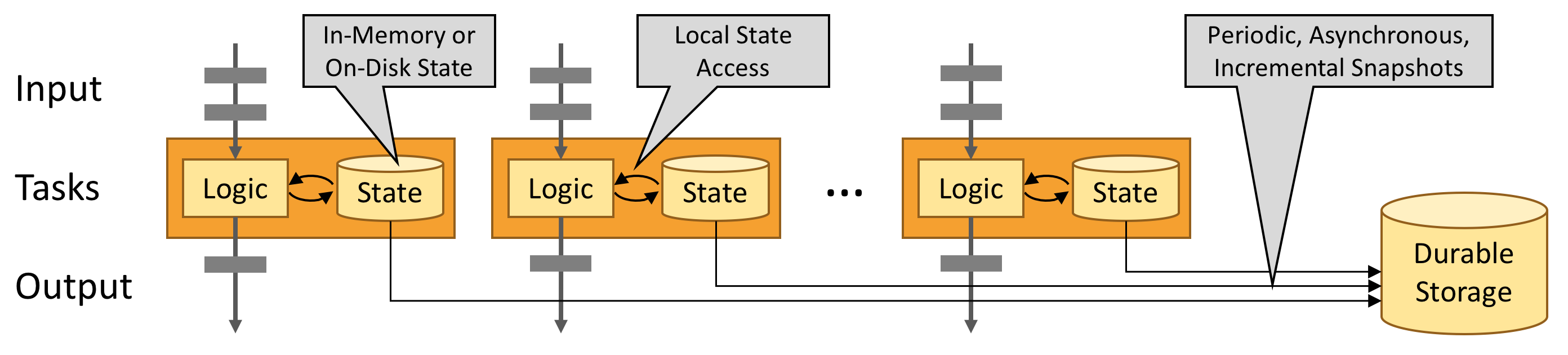
如何解释内存般的访问速度。
是指用户的逻辑始终需要不断的访问记录的状态,而这些状态被记录在内存里,这样访问就很快。当内存放不下的时候,会固化到硬盘里。另外,会定期的异步将当前的快照存放到硬盘里,以防止任务的重启能接着上次的终止的地方继续运算。如下图所示
运维
1. flink的时间和特点
flink提供了事件事件模式,即用事件发生时自身的时间戳来进行统计。好处是计算结果一定正确,坏处是可能有延迟。也就是即使是数据到达的不及时,也要保证结果的正确性。还有一种是处理时间模式,也就是用的是事件到达工作机的机器时间作为统计时间。这样做的好处是低延迟,坏处是可能结果不是那么的准确。
2. flink的checkpoint和savepoint
checkpoint是异步的增量的持久化的保存着,是为了机器故障的恢复。而savepoint则是为了集群的迁移,版本的升级而设计。在流式应用中,一个很大的难点是如何在线平滑的升级你的flink应用(业务代码,业务发布)。如果你的业务代码都重新发布了,那以前的计算的中间结果如何承接过来。总不能你一升级,用户的点击数就从0开始计算吧?flink使用savepoint很好的解决了这个难题。另外,还支持flink版本的平滑升级。