FullGC时间过长
问题
突然来了一波gc时间过长的告警,类似下面这个,接着接二连三的来了很多机器都是同样的
情况,看来集群同时发生了FullGC, 而且时间还不短。
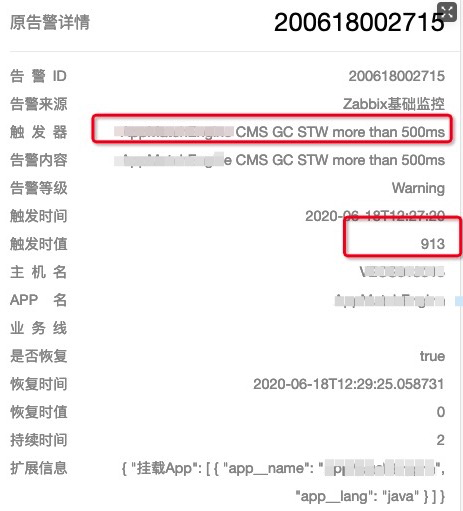

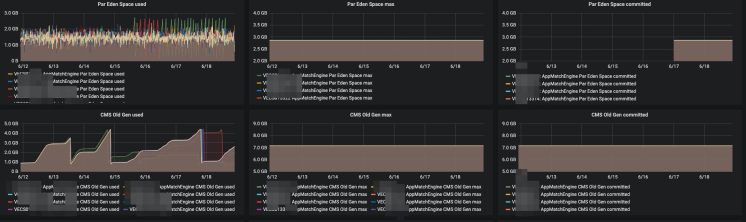
通常来说,fullGC也不是什么问题,即使你的GC时间超过了500ms,也没有影响业务, 没有上游业务的超时告警。但是你看看,这个old区的内存max最大设置了7个G, 而且我们每周至少发布一次,还发生了fullGC,就有点说不过去了,值得好好看一下. 有这么大的空间要GC,当然超过了500ms也不足为奇了.
2020-06-14T21:11:03.623+0800: 347435.070: [GC (CMS Final Remark) [YG occupancy: 1425258 K (3145472 K)]2020-06-14T21:11:03.624+0800: 347435.071: [Rescan (parallel) , 0.2118361 secs]2020-06-14T21:11:03.836+0800: 347435.283: [weak refs processing, 0.3505888 secs]2020-06-14T21:11:04.186+0800: 347435.634: [class unloading, 0.0493179 secs]2020-06-14T21:11:04.236+0800: 347435.683: [scrub symbol table, 0.0162566 secs]2020-06-14T21:11:04.252+0800: 347435.699: [scrub string table, 0.0022326 secs][1 CMS-remark: 4334730K(6990848K)] 5759989K(10136320K), 0.6480160 secs] [Times: user=1.97 sys=0.00, real=0.65 secs]
主要时间耗费在了scan和weak refs processing, 说明里面的对象非常多
一打开流量,old区就增加,一直到full gc. 一停止流量,old区就基本不变,这个太奇怪了。

heap dump分析开始推测
要分析gc问题,就离不开heap dump, 将机器拉下线,然后 jmap -dump:format=b,file=xxxxxx.hprof pid
进行dump,把dump文件压缩一下,不压缩有3个G, 压缩完只有400M,压缩比还是非常高的。
前几次没有压缩,使用sz从服务器上download,没有断点续传,一掉线就得从头开始。
继续看dump文件,发现里面有一些可疑的地方。
使用mat打开dump文件,使用Leak Suspects:功能,提示有三个问题。都是java自身的类,这就比较头大了。
我dump了很多次,挨个分析,
dump1的提示

dump2的提示

dump3的提示
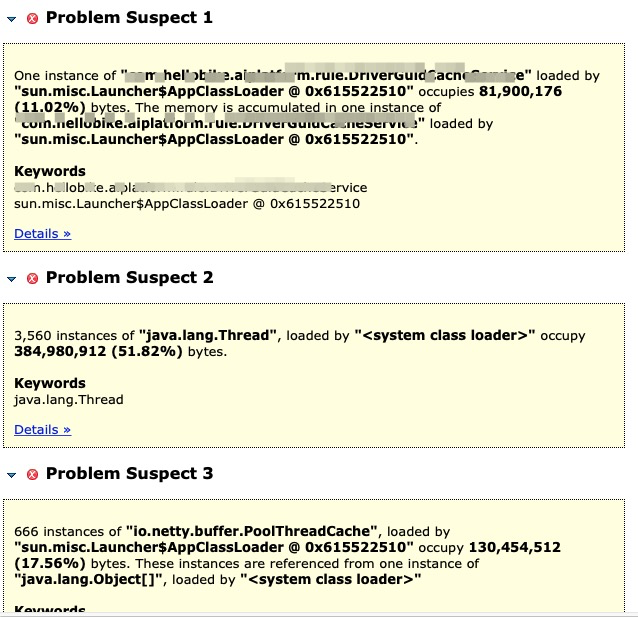
java.lang.Thread
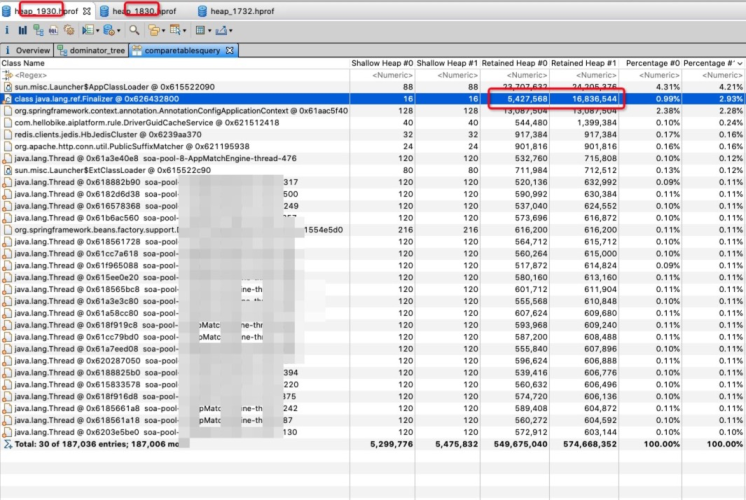
每个dump文件里都有java.lang.Thread的这个东西,于是打开tree看看,终于看到了熟悉的我们自己写的类,原来这是一个配置文件的类,他里面有很多的配置,有些配置本身比较大,是json对象,导致了占用了很多空间。再仔细看看,持有的这个对象在所有线程里都是同一个,内存地址一样的。所以虽然thread占据了空间,但是其实是同一个对象的重复统计了.而且可以明显的看到,每个线程的hetained heap大小基本一致, 所以这个暂时就先排除了。
java.lang.ref.Finalizer
那么是不是这个? java.lang.ref.Finalizer
打开tree进一步分析,发现java.lang.ref.Finalizer占了很多的内存。
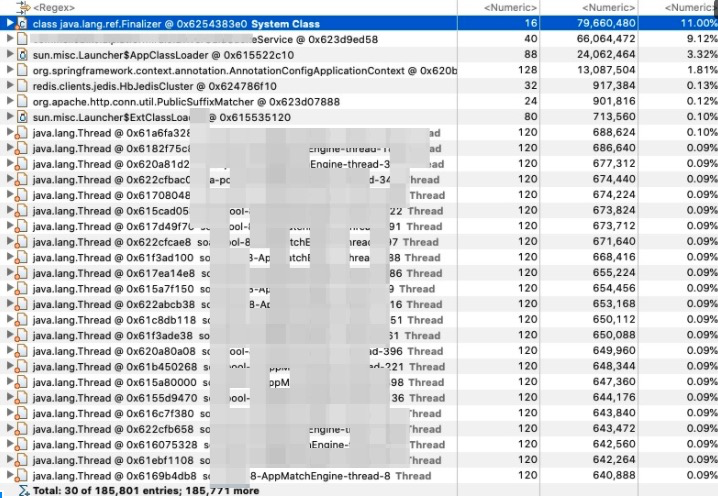
接着使用这个功能 , show retained set

打开看到了和java.net.SocksSocketImpl发生了关联

于是,一顿Google后了解到,Finalizer是一个优先级很低的资源回收线程,一般是实现了Object.finalize的类,会被这个线程给调用,由于他的优先级很低,所以轮不到他调度,要被调用的对象就被丢到队列里越积越多。而一般用户自己是不会去实现finalize这个方法的,恰恰SocksSocketImpl就实现了这个方法。这个是为了防止内存泄露,有的人忘记close,他会在SocksSocketImpl的finalize帮你去关闭资源。
这样的文章很多,可以搜 java.lang.ref.Finalizer memory leak 关键字.
恰好,我们的系统作为一个服务端,就是一个线程很吃紧的服务,因为各种原因,应用一共开了接近3000个线程,导致了Finalizer肯定是被调度不到了,也就造成了内存不断的增加,最后导致fullGC.
感觉很像。
到底是不是这个东西呢? 我分别dump了两次,一次是未接流量前,然后打开流量跑一个小时,再进行对比,对比发现Finalizer增加的非常快,看来是这个东西无疑了
寻找真凶
原理和推测我们基本搞清楚了,也算有了一个方向,那么我们就要寻找,到底是谁用了SocksSocketImpl这个东西,并且没有手动的close,放任他内存泄露呢?
这些都是jdk自己的类,而且是第三方的jar包调用的,不是业务代码,在代码里根本找不到关联。通过搜索SocksSocketImpl的调用方,根本关联不起来。这就非常头大了。
怀疑是不是内部的定时任务
看到代码里有两个定时任务,是从hdfs拉取模型数据的,最开始是怀疑这个东西,如果他没有用线程池,每次都发起新的连接,然后又不关闭的话,应该是会导致内存泄露的,能够和我们的分析对的上号。
但是奇怪的是,流量停止了之后为什么就不增加了呢? 而流量停止了,我们的定时任务实际上仍然是在执行的。这个有点悖论,讲不通。
使用Arthas大杀器继续寻找真凶
将流量拉下线之后,我们使用Arthas这个大杀器。这个是使用了javaaent的技术,注入到原有的代码里,跟踪代码的运行情况的。我们使用trace功能,trace一下到底是谁new SocksSocketImpl这个东西。
trace java.net.SocksSocketImpl *init* . 最开始用构造函数SocksSocketImpl不成功,使用sm java.net.SocksSocketImpl打开类里面加载的到底是个什么东西,发现函数不是SocksSocketImpl而是叫init.

虽然没啥有用的信息,但是找到了一条关键的线索: commons-pool-evictor-thread, 又去Google发现是redis client使用的commons-pool线程池引进来的。
然后打开这个线程池的类,再去搜哪里用到了他,依然是搜不到的,再次陷入了僵局。
jstack把线程打出来,依然找不到任何线索,那么这个东西到底是如何work的呢?
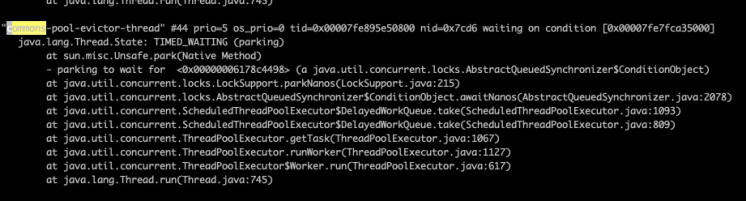
本地debug开启,打开断点,停在断点的时候,可以看到调用的堆栈。发现果然是redis拉起来的,这是一个定时任务,从evictor这个单词可以看出,这个东西就是清除空闲线程作用的。这就很奇怪了,清楚空闲的线程跟SocksSocketImpl是如何关联上的呢? 代码又不能搜索被谁用的,太麻烦了。
既然是定时程序,那么肯定也就跟流量无关了,本地也可以触发。于是把SocksSocketImpl打满了断点,
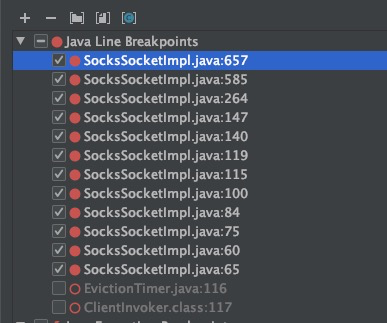
总算捕获到了这个断点,然后从idea的调用栈里面去寻找。理清楚了他们之间的关系。
原来系统起来的时候,会去初始化redis client, redis.clients.jedis.connect这个类被初始化的时候,就会拉起一个定时任务来清楚空闲的线程,线程名字就叫做 commons-pool-evictor-thread, 接着这线程开始工作。
这个线程是属于commons-pool这个池化的jar包里的内容,跟业务其实是不相关的。
这个线程的入口在
org.apache.commons.pool2.impl.BaseGenericObjectPool.Evictor.run
这个run干了两件事, 先evict清楚空闲线程,再重新创建.
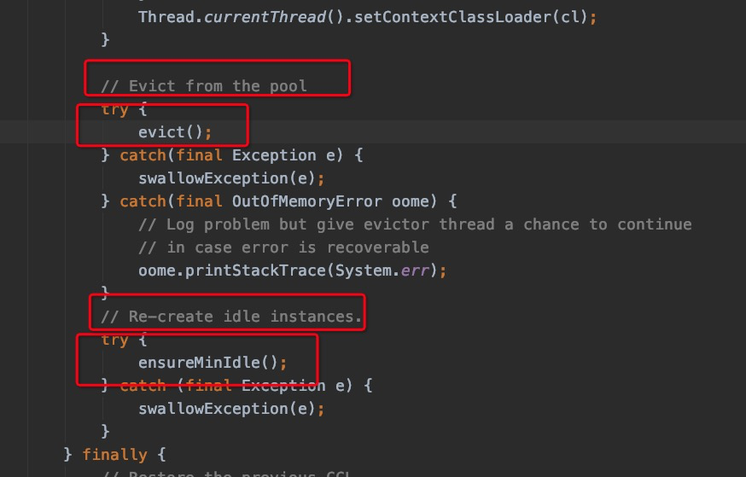
如何去清楚空闲线程呢?
evict = evictionPolicy.evict(evictionConfig, underTest,
idleObjects.size());
在这个方法里,这个underTest记录了最后使用的时间,然后和当前的时间比较,如果超过了空闲的时间(有默认配置), 就会把他干掉。
org.apache.commons.pool2.impl.GenericObjectPool.ensureIdle这个方法就是重新拉起一个连接,具体实现在
JedisFactory.makeObject里的 jedis.connect();这行代码,redis.clients.jedis方法如下
public void connect() { if (!this.isConnected()) { try { this.socket = new Socket(); this.socket.setReuseAddress(true); this.socket.setKeepAlive(true); this.socket.setTcpNoDelay(true); this.socket.setSoLinger(true, 0); this.socket.connect(new InetSocketAddress(this.host, this.port), this.connectionTimeout); this.socket.setSoTimeout(this.soTimeout); if (this.ssl) { if (null == this.sslSocketFactory) { this.sslSocketFactory = (SSLSocketFactory)SSLSocketFactory.getDefault(); } this.socket = this.sslSocketFactory.createSocket(this.socket, this.host, this.port, true); if (null != this.sslParameters) { ((SSLSocket)this.socket).setSSLParameters(this.sslParameters); } if (null != this.hostnameVerifier && !this.hostnameVerifier.verify(this.host, ((SSLSocket)this.socket).getSession())) { String message = String.format("The connection to '%s' failed ssl/tls hostname verification.", this.host); throw new JedisConnectionException(message); } } this.outputStream = new RedisOutputStream(this.socket.getOutputStream()); this.inputStream = new RedisInputStream(this.socket.getInputStream()); } catch (IOException var2) { this.broken = true; throw new JedisConnectionException("Failed connecting to host " + this.host + ":" + this.port, var2); } } }
可以清楚的看到是 new Socket();打开了一个连接,而因为是连接池的原因是不能关闭的。
找到问题
最终我们知道了, 确实redis client导致了不断的去new Socket(). 最开始走了弯路是因为,我问了负责的开发,我们的系统是没有用redis的。那为什么会出现redis client呢? 原因是我们的代码的算法模块来自于以前叫gateway的应用,这个应用依赖了redis,迁移过来的时候没有删除。因为单单删除application.yml里的redis的配置,系统起不来,只好保留了。
仔细来看,其实是因为pom.xml一旦引入了redis-spring-boot的依赖,他就会尝试初始化一个redis的client出来,如果application.yml里少了redis的配置,那当然是起不来的。
验证
还是找这台机器,修改配置,删除redis-spring-boot的jar包重启应用进行观察. 首先old区的增长没有那么快了

别的机器是这样的
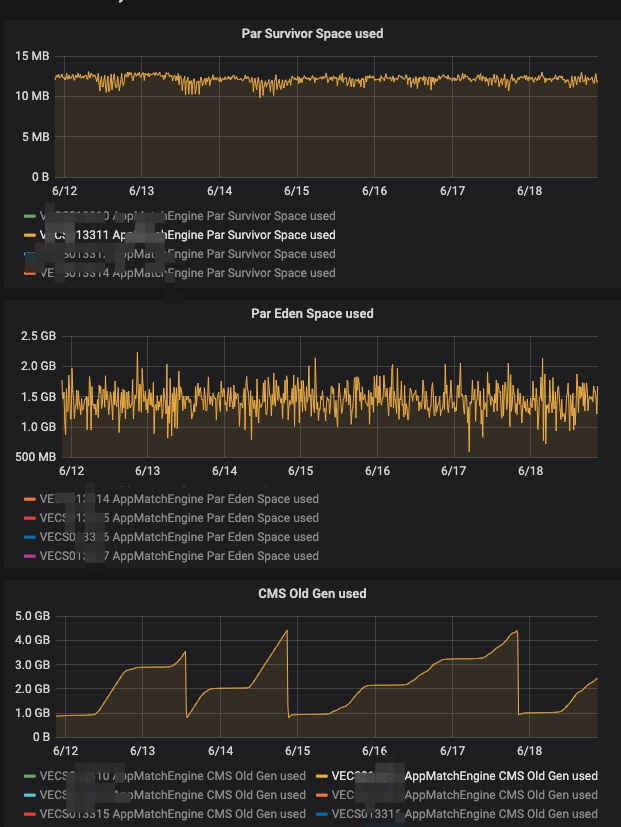
首先old区增长没有这么快了,另外就是young区gc完了之后,释放了更多的内存,说明更多的对象在youngGC的时候就已经清理掉了.
还需要更长时间,更多的观察数据,发布前最近7天的数据