背景
距离上次排查cpu异常问题已经过去了至少5年了,那个时候刚接触Java就遇到了hashmap导致的cpu100%问题,茫然无措的时候那叫一个难,现在我们有了基本的常识之后,就不慌了,按照排查思路排查,一定能发现问题。
新代码发布到生产之后,出现了性能问题,cpu异常的飙高,但是又未到100%,通过压测发现性能下降的很厉害,qps不到10的时候,cpu就被打满了。那么cpu到底用在了什么地方呢? 因为本次发布的改动点,就是算法排序模块,这个模块也是整个系统里最耗费cpu的地方,所以从这里开始入手排查。
我们回想一下,Java里常见的cpu异常最可能是什么原因?
第一个最常见的就是hashmap的不正确的使用,这个是多线程里经典的面试问题,但是这个表现一般是cpu直接到100%,我们这应用cpu未到100%,只是表现异常,在同样流量的情况下,比正常代码cpu要高出很多,基本可以排除是这个问题。
第二个常见的就是写了一个死循环。这个时候的cpu占用也会直接是100%,像我们这种情况下,cpu一定是在大量的进行计算,应该都不满足以上两种情况
问题排查
压测环境
幸运的是,我们的异常问题非常容易复现,不是偶发的(偶发的查起来更加困难),拥有一个压测环境就显得非常有帮助了。首先我们把压测环境搭建好,然后进行我们的实验和猜测。
常用cpu异常排查办法
要定位到问题,我们首先要知道是哪行代码导致了cpu的使用异常,常用的排查手段无非是要快速找到线程名称。
使用java自带Jstack进行排查
这种常规的排查手段,搜索引擎上非常多,通过pid定位到占用cpu最多的线程号,然后转成16进制,再到jstack里打印出来的线程详情里取搜索,定位到线程名称。
线程名称就显得非常重要了,他能让你直接定位到代码,这也是我们在使用线程池的时候,强调的一定要给线程取名字的原因。你搞一个默认的名字,出现这种问题了,你无法准确定位到问题代码。
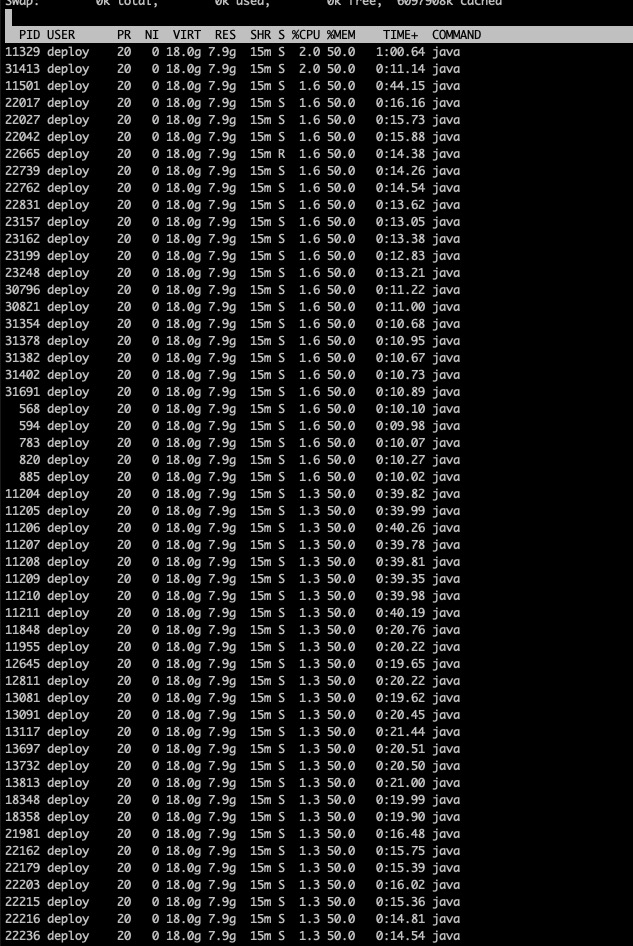
所有的线程打印出来如上图所示,可以看到每个线程占用的cpu几乎是差不多的,没有特别高的出现。这可就难了,这个就说明了是业务逻辑写的有问题,而不是代码有什么问题。也就是这些线程确实是都在认认真真的工作,并没有出现某个线程抢占了cpu的情况。
使用阿尔沙斯排查
Java界有一个非常好用的问题排查工具,也是我经常使用的工具arthas,用来排查gc问题和cpu问题以及各种java问题非常的得心应手。他的原理使用javaagent注入到原java线程里,拿到一些有用的监控信息。具体如何使用,可以参考官方文档。
排查cpu问题可以使用, thread -n 3 ,就是查看最耗cpu的前3的线程,顺带会给你把代码调用栈给你打出来,如下图所示:

其实这个时候基本可以定位到是什么问题了,因为问题代码都给你打出来了。这个时候我严重的怀疑是计算规模扩大了,可以从上面的打印栈中看到代码都是正常的代码,那是不是这个ArrayList特别大,而每个循环都是cpu密集型,导致了cpu占用了。是不是代码有问题,导致了这个ArrayList变大了?最后发现确实是的,可惜的是当时被忽略了,看来有时候还是要相信直觉
实际上Arthas只是简化了使用Jstack的使用方法,本质还是要拿到线程名称,以及代码栈
猜测和验证
gc问题导致?
最开始开发怀疑是gc问题,因为他观察到相对于正常代码,新代码的gc更加频繁,而且gc的时间更长。但是我觉得这个应该只是结果而不是原因。首先如果是gc问题,那么通过jstack的排查手段,应该能定位到所有的cpu都耗费在了gc的线程上(gc的线程名称是固定的),我们通过jstack的信息看到的并不是这样的。另外一个方面,你的cpu都被你业务用掉了,这个时候gc线程优先级很低,当然争取不到cpu资源了,gc的时间变成了,也就顺理成章了。
后来经过调整内存大小,减少了gc次数,但是cpu的表现跟没调整一模一样,没有任何变化,可见就排除了gc的嫌疑了。
线程切换导致?
通过fastthread.io上次你的jstack打印出来的日志,发现线程数很多,达到了3000多个,然后通过 vmstat命令看到线程切换特别频繁,所以怀疑是因为线程数太多,cpu都耗费在了线程切换上了
vmstat每一列信息对照表
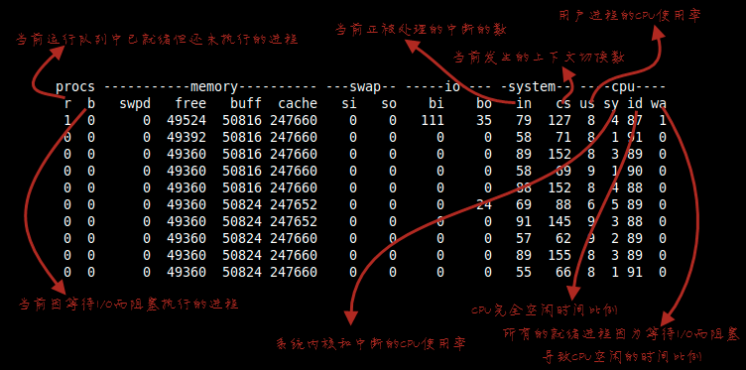
于是,我们把线程数改小了一半,通过压测发现cpu没有任何改善,如果是这个问题,问题不说完全解决,至少应该会下降一个量级,但是没有任何改变,就说明了不是这个问题。
日志打印导致? log4j的版本问题
https://blog.csdn.net/qq_17231297/article/details/106621820
无意中看到上面这篇文章,再结合Arthas打印出来的代码栈,怀疑是不是打印日志导致的,结果把所有的info日志关闭之后,再压测,问题依旧没有任何改变,说明也不是这个问题。
其他排查手段
常规的排查手段都失效了,只能通过排除法来一行一行的定位问题代码了。通过注释掉怀疑的代码,反复的压测,来定位问题代码具体位于哪一行。如果最后定位到了的那行代码是正常的代码,跟旧代码没有任何差异,那肯定就是你的计算次数变多了导致。
问题定位
一直一直都是怀疑代码有问题导致的计算规模变大了,经过旁边同学仔细的查看代码的确如此。我们常常犯的一个错误就是循环的时候变量搞混,下面这行代码循环的时候,传进来的却还是原来的大数组,而不是拆解之后的小数组。

总结
问题排查是自身技术提升最快的方法,要好好珍惜公司给你提供的免费练手机会,尤其很多故障都是有资损的,相当于公司出钱给你练手了。
通过这次的问题复盘,你可以掌握以下知识点,我觉得最重要的不是你解决了问题,而是你从中学到了什么
