目的: 订阅kafka的消息(kafka的消息是从postgresql来的),将kafka的消息作为TableSource,执行sql,将结果输出到ElasticSearch中
动态表格
flink的概念里,stream的输入是一个insert的模式。类似于点击日志这种,是源源不断的产出的新数据。而postgresql到kafka的消息包含了insert,update和delete的操作。
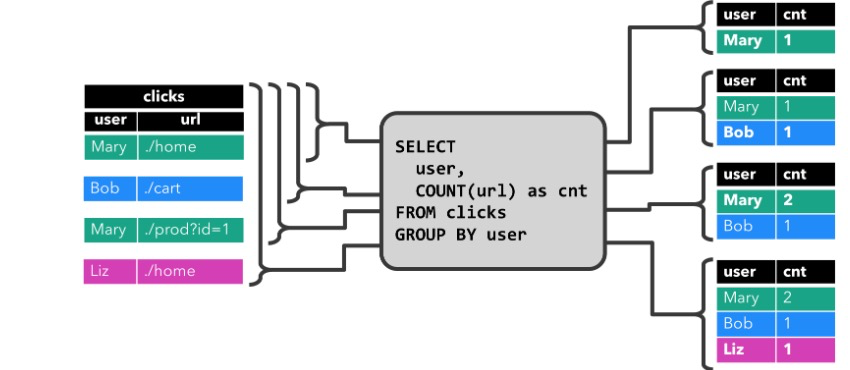
在点击日志的概率里,如果统计点击次数,比较好理解。一种是表格不断的更新(update mode)。如果unique key第一次出现,则插入,否则做累加,类似下面这种
{kind=link}
还有一种则是基于窗口的统计,每一个窗口期插入一系列的数据,所以这个是insert模式
{kind=link}
但是在我们的场景里面,kafka里的消息不仅仅是插入的数据,还有可能是更新的数据。也就是有个维表,里面的数据在不断的更新。
那么现在就是要搞清楚一件事。如果我定义了一个Table,接受Stream data数据不断流入。如果我这个table里不存在这表数据(定义primary key),那么他就会执行插入。否则他会执行update操作。我们写代码来试验一下这个想法, 看看是不是这样。如果没有group by 语句,你连primary key 都定义不了,也就没办法实现更新了…..所以要区分情况,如果你是上面的例子,通过group by 计算count, 因为有primary key,所以可以形成动态表格,可以自动update.如果你仅仅是接受kafka的消息,scan模式的话,由于表格没有primary key,所以是不支持update,而只支持insert的。
所以针对update 和 delete 还需要单独处理….
在Table convert to DataStream一章里,使用了Tuple2<Boolean, Row>这个数据结构来区分Reactor Mode. 其中那个Boolean// True is INSERT, false is DELETE.